Program
FPT’22 is held as a hybrid conference. The physical venue is Room 1038, IAS building, HKUST. We use Whova as the virtual platform. You must register (there is a free option) to attend the virtual events. The program is below (subject to change). All times in Hong Kong Time (HKT), which is UTC+8.
For each paper a (pre-recorded) presentation video will be available beforehand. During the conference, each paper is presented with a live talk with Q&A session.
Overview
| Time | Mon, 5 Dec Workshop/ Tutorials |
Time | Tue, 6 Dec Workshop/ Tutorials |
Time | Wed, 7 Dec Day 1 |
Time | Thu, 8 Dec Day 2 |
Time | Fri, 9 Dec Day 3 |
|---|---|---|---|---|---|---|---|---|---|
| 9:30am-1:30pm | Workshop/ Tutorials 1 |
9:30am-12:30pm | Workshop/ Tutorials 3 |
9:30am-9:50am | Opening Session | 9:30am-10:30am | Keynote 2 | 9:30am-10:30am | Keynote 3 |
| 9:50am-10:50am | Keynote 1 | Coffee Break | Coffee Break | ||||||
| Coffee Break | 10:50am-12:20pm | Application 1 | 10:50am-11:50am | Architecture 2 | |||||
| 11:10am-12:20pm | AI/ML | 11:50am-12:20pm | Poster Session 2 | ||||||
| Lunch | Lunch | Lunch | |||||||
| 3:00pm-5:00pm | Workshop/ Tutorials 2 |
2:00pm-5:00pm | Workshop/ Tutorials 4 |
1:30pm-3:10pm | Journal Session | 1:30pm-2:50pm | Tools & Design | 1:30pm-3:10pm | Application 2 |
| Coffee Break | Coffee Break | Coffee Break | |||||||
| 3:30pm-4:20pm | Architecture 1 | 3:10pm-5:10pm | Design Competition | 3:30pm-4:10pm | PhD Forum | ||||
| 4:20pm-4:50pm | Poster Session 1 | 6:00pm-9:30pm | Banquet | 4:10pm-4:30pm | Closing & Best Paper Award |
Main Day 1
Main Day 2
| Time | Main Day 2: Thursday 8th December 2022 |
|---|---|
| 9:30am - 10:30am | Keynote 2 (Chair: Prof. Yun Eric Liang) Prof. Wang Yu, Tsinghua University Heterogeneous Acceleration for Multi-DNN workloads: Progress and Trends |
| 10:30am - 10:50am | Coffee Break |
| 10:50am - 12:20pm | Application 1 (Chair: Prof. Jiafeng Xie) ▸ SALIENT: Ultra-Fast FPGA-based Short Read Alignment, Behnam Khaleghi, Tianqi Zhang, Cameron Martino, George Armstrong, Ameen Akel, Ken Curewitz, Justin Eno, Sean Eilert, Rob Knight, Niema Moshiri and Tajana Rosing; Best Paper Candidate  Artifact: Available Artifact: Available▸ Bandwidth-Efficient Homomorphic Encrypted Matrix Vector Multiplication Accelerator on FPGA, Yang Yang, Sanmukh R. Kuppannagari, Rajgopal Kannan and Viktor Prasanna ▸ Hypersort: High-performance Parallel Sorting on HBM-enabled FPGA, Soundarya Jayaraman, Bingyi Zhang and Viktor Prasanna ▸ ZHW: A Numerical CODEC for Big Data Scientific Computation, Michael Barrow, Zhuanhao Wu, Scott Lloyd, Maya Gokhale, Hiren Patel and Peter Lindstrom Artifact: Available, Evaluated Functional▸ Boosting Domain-Specific Debug Through Inter-frame Compression, Zakary Nafziger, Martin Chua, Daniel Holanda Noronha and Steven J.E. Wilton Artifact: Available▸ Short Paper Parallel CRC On An FPGA At Terabit Speeds, Qianfeng Shen, Juan Camilo Vega and Paul Chow Artifact: Available▸ Short Paper A Cautionary Note on Building Multi-tenant Cloud-FPGA as a Secure Infrastructure, Yukui Luo, Yuheng Zhang, Shijin Duan and Xiaolin Xu |
| 12:20pm - 13:30pm | Lunch |
| 1:30pm - 2:50pm | Tools & Design (Chair: Prof. Kan shi) ▸ FADEC: FPGA-based Acceleration of Video Depth Estimation by HW/SW Co-design, Nobuho Hashimoto and Shinya Takamaeda-Yamazaki Artifact: Available, Evaluated Functional, Evaluated Reusable, Results Replicated▸ Automated Generation and Orchestration of Stream Processing Pipelines on FPGAs, Kaspar Matas, Kristiyan Manev, Joseph Powell and Dirk Koch ▸ P3Net: PointNet-based Path Planning on FPGA, Keisuke Sugiura and Hiroki Matsutani ▸ byteman: A Bitstream Manipulation Framework, Kristiyan Manev, Joseph Powell, Kaspar Matas and Dirk Koch; Best Paper Candidate ▸ Short Paper Area-Efficient Memory Scheduling for Dynamically Scheduled High-Level Synthesis, Xuefei He, Jianyi Cheng and George Constantinides Artifact: Available, Evaluated Functional, Evaluated Reusable, Results Replicated▸ Short Paper Efficient Reinforcement Learning Framework for Automated Logic Synthesis Exploration, Yu Qian, Xuegong Zhou, Hao Zhou and Lingli Wang |
| 2:50pm - 3:10pm | Coffee Break |
| 3:10pm - 5:10pm | Design Competition: Autonomous Vehicle Driving using FPGAs (Chair: Prof. Minoru Watanabe)
The competition will be held in a separate venue at Okayama University, Japan, and will be real-time broadcasted through the conference virtual platform. People in the physical venue in Hong Kong can also watch the live stream! Check the link for more infomation! ▸ Hardware SAT Solver-based Area-efficient Accelerator for Autonomous Driving, Yusuke Inuma and Yuko Hara-Azumi ▸ A Lane Detection Hardware Algorithm Based on Helmholtz Principle and Its Application to Unmanned Mobile Vehicles, Katsuaki Kamimae, Shintaro Matsui, Yasutoshi Araki, Takehiro Miura, Keigo Motoyoshi, Keizo Yamashita, Haruta Ikehara, Takuho Kawazu, Huang Yuwei, Masahiro Nishimura, Shuto Abe, Kenyu Okino, Yuta Hashiguchi, Koki Fukuda, Kengo Yanagihara, Taito Manabe and Yuichiro Shibata ▸ Desgin and Implementation of ROS2-based Autonomous Tiny Robot Car with Integration of Multiple ROS2 FPGA Nodes, Hayato Mori, Hayato Amano, Akinobu Mizutani, Eisuke Okazaki, Yuki Konno, Kohei Sada, Tomohiro Ono, Yuma Yoshimoto, Hakaru Tamukoh, Takeshi Ohkawa and Midori Sugaya ▸ Autonomous driving system with feature extraction using a binarized autoencoder, Kota Hisafuru, Ryotaro Negishi, Soma Kawakami, Dai Sato, Kazuki Yamashita, Keisuke Fukada and Nozomu Togawa ▸ Implementation and Improvement of Autonomous Robot Car using Soc FPGA with DPU, Akira Kojima |
| 6:00pm - 9:30pm | Banquet |
Main Day 3
Opening Session Speakers
Prof. Tim Cheng, The Hong Kong University of Science and Technology (HKUST)

Bio: Professor Tim Cheng is Vice-President for Research and Development (VPRD) and Chair Professor jointly in the Electronic & Computer Engineering (ECE) and Computer Science & Engineering (CSE) Departments at The Hong Kong University of Science and Technology (HKUST). He is also the Director of InnoHK AI Chip Center for Emerging Smart Systems which aims to advance IC design to help realize ubiquitous AI applications in society.
At HKUST, Prof. Cheng served as Dean of Engineering for 6 years prior to taking the current role of VPRD. Prior to joining HKUST in 2016, he was on the faculty of the University of California, Santa Barbara where he also served in various administrative roles including ECE Department Chair and Associate Vice-Chancellor for Research.
An internationally leading researcher with extensive experience in fostering cross-disciplinary research collaboration, Prof. Cheng is a world authority in the field of electronics design verification and testing, as well as covering a wide range of research areas including design automation of electronic and photonic systems, computer vision, and medical image analysis.
Keynote Speakers
Prof. James C. Hoe, Carnegie Mellon University
Title: FPGA Technology at Crossroads

Abstract: Field Programmable Gate Arrays (FPGAs) have been undergoing rapid and dramatic changes fueled by their expanding use in datacenter and machine learning. Rather than serving as a compromise or alternative to ASICs, modern FPGA 'programmable logic' is emerging as a third paradigm of compute that stands apart from traditional hardware vs. software archetypes. The Intel/VMware Crossroads 3D-FPGA Academic Research Center is a multi-university collaborative research to define a new role for programmable logic in future datacenter servers. Guided by both the demands of modern network-driven, data-centric computing and the new capabilities from 3D integration, this center is developing the Crossroads 3D-FPGA as a new central fixture component on future server motherboards, serving to connect all server endpoints (network, storage, memory, CPU) intelligently. As a literal crossroads of data, a Crossroads 3D-FPGA can apply application-specific functions over data-on-the-move between any pair of server endpoints, intelligently steer data to the right core or accelerator, and reduce the volume of data that needs to be moved between servers. This talk will overview the Crossroads 3-D FPGA concepts, as well as the associated set of research thrusts to pursue a full-stack solution spanning application, programming support, dynamic runtime, design automation, and architecture.
Bio: James C. Hoe is a Professor of Electrical and Computer Engineering at Carnegie Mellon University. He received his Ph.D. in EECS from Massachusetts Institute of Technology in 2000 (S.M., 1994). He received his B.S. in EECS from UC Berkeley in 1992. He is interested in many aspects of computer architecture and digital hardware design, including the specific areas of FPGA architecture for computing; digital signal processing hardware; and high-level hardware design and synthesis. He is the lead PI of the Intel/VMware Crossroads 3D-FPGA Academic Research Center. He is a Fellow of IEEE. For more information, please visit the link.
Prof. Yu Wang, Tsinghua University
Title: Heterogeneous Acceleration for Multi-DNN workloads: Progress and Trends

Abstract: We have witnessed the rapid growth of heterogeneous domain specific acceleration for deep neural networks (DNNs) in the past decade. For general artificial intelligence (AI) scenarios, especially autonomous driving and cloud computing, the computing power of AI chips is moving toward hundreds or thousands of tera operations per second (TOPS). Meanwhile, the number of DNN models is also increasing, and their types are diversifying. Currently, there is still a gap between single-model latency-optimized AI chips and multi-model versatility-oriented application requirements, leading to severe resource underutilization and sub-optimal system performance.
This talk will first examine the challenges of supporting multi-DNN workloads on traditional monolithic DNN accelerators. Second, this talk will present recent progress of enabling multi-tenancy in the architecture design of DNN accelerators. Third, this talk will envision a future where a coordinated architecture, scheduling, and mapping optimization approach would provide a great improvement on heterogeneous acceleration for multi-DNN workloads.
Bio: Yu Wang, professor, IEEE fellow, chair of the Department of Electronic Engineering of Tsinghua University, dean of Institute for Electronics and Information Technology in Tianjin, and vice dean of School of information science and technology of Tsinghua University. His research interests include the application specific heterogeneous computing, processing-in-memory, intelligent multi-agent system, and power/reliability aware system design methodology. Yu Wang has published more than 80 journals (56 IEEE/ACM journals) and 200 conference papers in the areas of EDA, FPGA, VLSI Design, and Embedded Systems, with the Google citation more than 14,000. He has received four best paper awards and 11 best paper nominations. Yu Wang has been an active volunteer in the design automation, VLSI, and FPGA conferences. He will serve as TPC chair for ASP-DAC 2025. He serves as the editor of important journals in the field such as ACM TODAES and IEEE TCAD and program committee member for leading conferences in the top EDA and FPGA conferences.
Prof. Taisuke Boku, University of Tsukuba
Title: How FPGA can compensate with High Performance Computing

Abstract:
Today's HPC (High Performance Computing) is supported by accelerator
technology to provide very high performance/power ratio which is not
enough by general purpose CPUs. The most popular player as the
accelerators is GPU which provides highly parallel computing elements
under efficient manner to concentrate a large part of power
consumption just for computation while many-core CPUs need a large
portion for complicated instruction control.
Although the latest GPU's absolute performance is so high to overcome
50TFLOPS per device, it is mainly usable for high degree of "spatial"
parallelism of the target applications to be applied SIMD (Single
Instruction Multiple Data) manner control. In some applications which
are constructed with multiple phenomena with variation of partial
algorithm and degree of parallelism, GPU computation is not perfect,
and these even small fraction of computation bottlenecks the total
performance. We have been researching how FPGA can compensate with GPU
to attack such a problem. It is well known that the absolute
performance (FLOPS) of FPGA is far from the advanced GPUs, however the
computation model of FPGA is based on the combination of pipeline
parallelism and spatial one, and we can expect very high efficiency
when combining these devices for a single application.
In this talk, I will introduce our concept of such a multi-hybrid
acceleration named CHARM (Cooperative Hybrid Acceleration with
Reconfigurable Multi-devices), and the hardware and software systems
we have been developing as well as a typical application which is
accelerated one order of magnitude from GPU-only solution. We are
running a supercomputer named Cygnus which is the world first
multi-hybrid accelerated system with GPU and FPGA coupling, and I
also introduce how the system is used now.
Bio: Taisuke Boku has been researching HPC system architecture, system software, and performance evaluation on various scientific applications after he received PhD degree of Electrical Engineering from Keio University, Japan. He is currently the director of Center for Computational Sciences, University of Tsukuba, a co-designing center with both application researchers and HPC system researchers. He has been playing a central roles for development of original supercomputers in the center including CP-PACS (ranked as number one in TOP500 in 1996), FIRST, PACS-CS, HA-PACS and Cygnus systems, the representative supercomputers in Japan. The recent system Cygnus is the world first multi-hybrid accelerated system with GPU and FPGA together. He has been the President of HPCI (High Performance Computing Infrastructure) Consortium in Japan in 2020-2022. He was a member of system architecture working group of Fugaku supercomputer development. He received ACM Gordon Bell Prize in 2011.
Workshop/Tutorials
Workshop/Turtorial Chairs: Sharad Sinha (IIT Goa) and Peter Chun (Huawei)
Title: OpenFPGA
Organizers: Pierre-Emmanuel Gaillardon (University of Utah, OSFPGA Foundation), Nanditha Rao (IIIT Bangalore), Tony McDowell (OSFPGA Foundation) and Aman Arora (University of Texas, Austin)
Description: Create your own FPGA! Check more details at the link. Note that there is a separate registration entry for this workshop, please kindly see this form.
Date and Time: 5th December 2022, 9:30am - 1:30pm
Mode: Online (Live link is available in the virtual platform)
Title: Using Intel FPGA High-Level Synthesis Interfaces, a Hands-On Tutorial
Organizers: Intel Labs
Description: The Intel® HLS Compiler is a high-level synthesis (HLS) tool that takes in untimed C++ as input and generates production-quality Verilog code that is optimized for Intel® FPGAs. In this tutorial, you will learn about the various component interfaces that can be generated by the Intel® HLS Compiler and how to infer them in your code. The interfaces covered include conduit interfaces, and Avalon memory-mapped host and agent interfaces, and Avalon streaming interfaces. The attendees will perform a hands-on lab that will give them practice generating components with different interfaces.
Date and Time: 5th December 2022, 3:00pm - 5:00pm
Mode: Online (All registered attendees can join the workshop and a Teams meeting link is available in the virtual platform)
Title: Enabled Car Plate Recognition using AI – Explore the Power of Xilinx SoC
Organizers: AVNET and HKSTP
Description: This 3-hours course will help engineers jump start the development of an AI design on Xilinx SoC device using Avnet Ultra96 development board, a cost-optimized development platform for embedded vision and industrial IoT systems. The workshop will introduce Xilinx MPSOC device, Vitis AI tools, AI ModelZoo and deploy Automatic Number Plate Recognition (ANPR) on Avnet Ultra96 board. Through simple step-by-step procedure, participants will complete an AI design on an embedded processor in just few hours! Go register here!
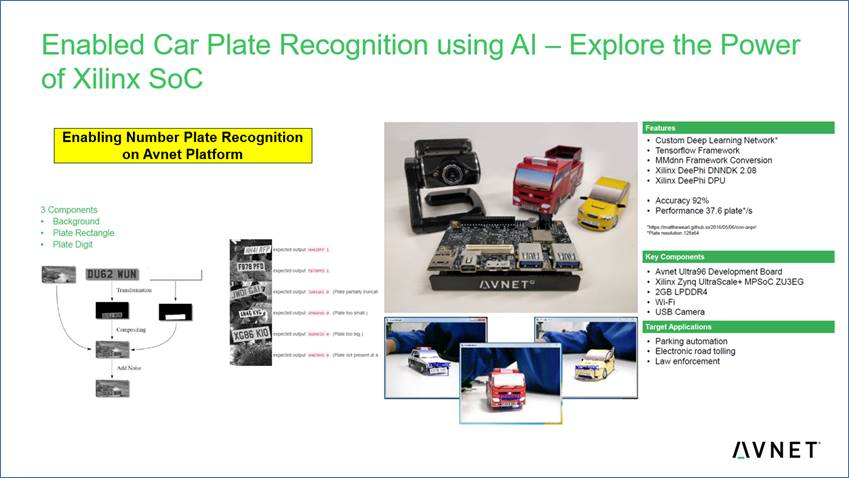
Date and Time: 6th December 2022, 9:30am - 12:30pm
Mode: Online training, and live link is available in the virtual platform
Title: Enable Research with Heterogeneous Accelerated Compute Clusters
Organizers: AMD Xilinx, NUS
Description:
-
Heterogeneous Accelerated Compute Clusters (HACC) Introduction
-
Parallel Graph Processing Accelerators on FPGAs, Dr. Yao Chen, Assistant Professor, NUS
-
Improving Energy Efficiency of Permissioned Blockchains Using FPGAs, Dr. Haris Javaid, SMTS, AMD Xilinx
-
HACC Tutorial, Dr. Hongshi Tan, NUS
Date and Time: 6th December 2022, 2pm - 5pm
Mode: Online (All registered attendees can join the workshop and a Zoom meeting link is available in the virtual platform)